

软件信息
-
软件大小
542.8 MB -
更新时间
-
兼容平台
MacOS 13.x,MacOS 12.X -
积分
100积分(vip免费) -
语言
英文软件 -
分类
网络工具
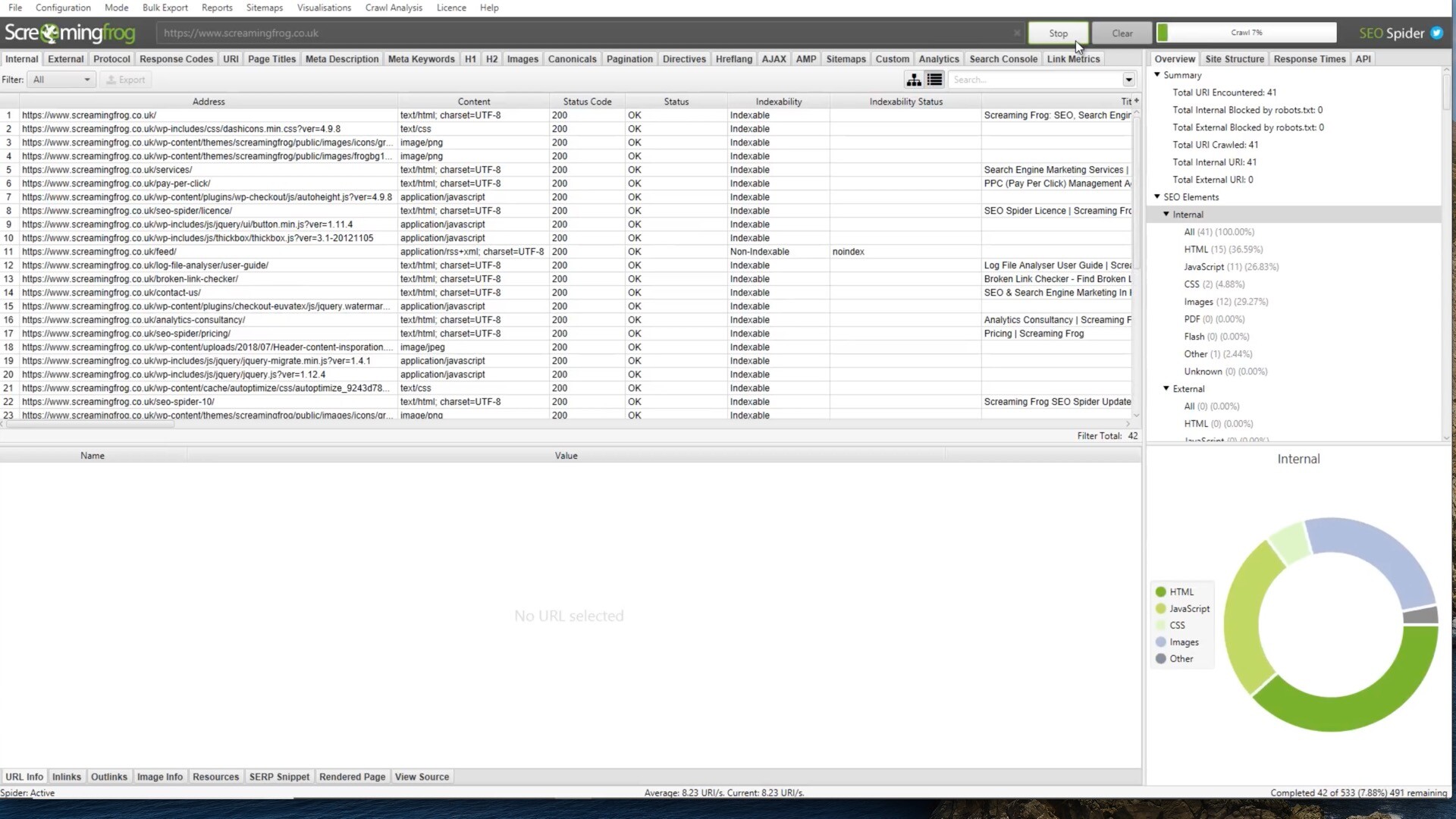
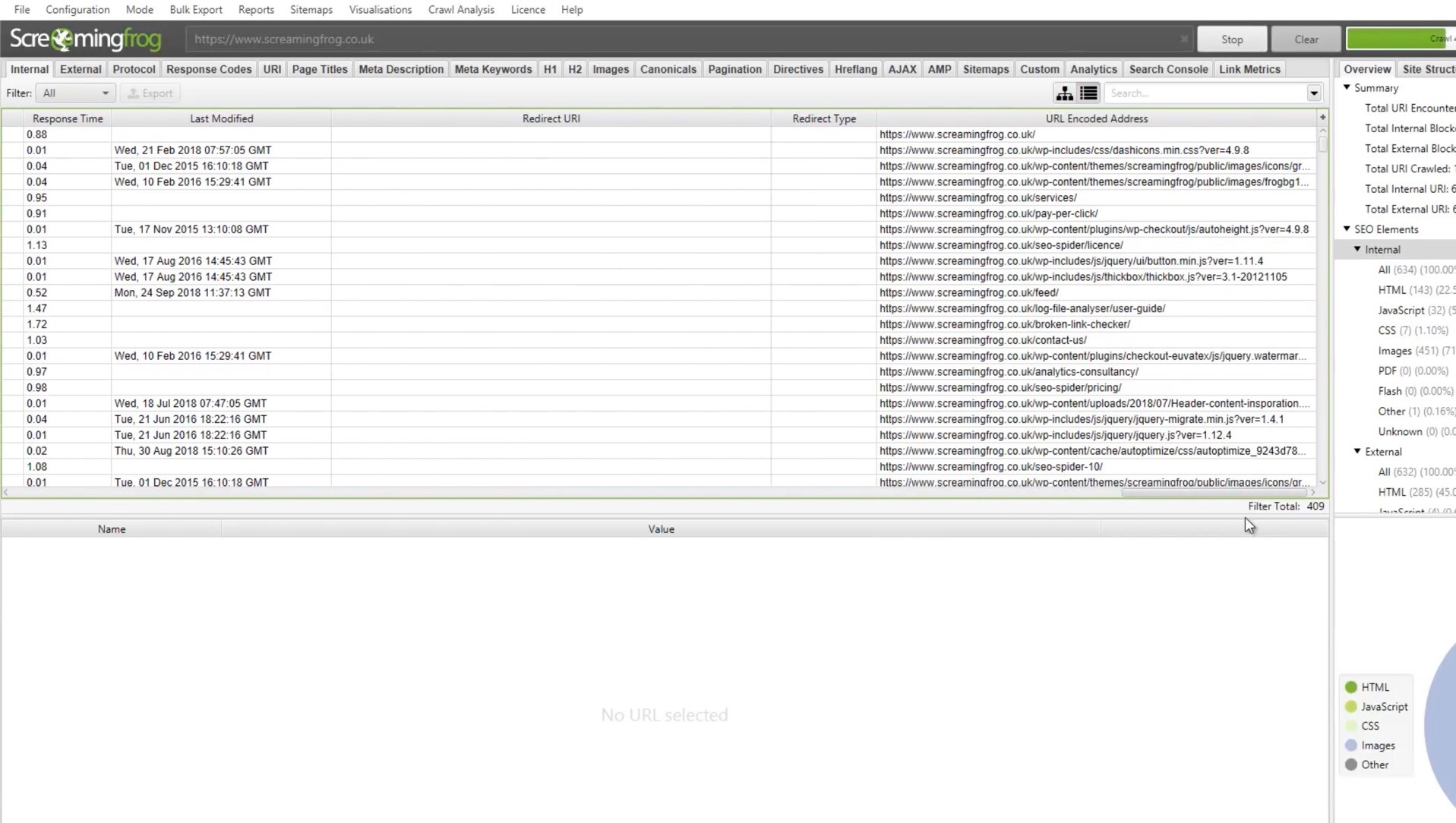
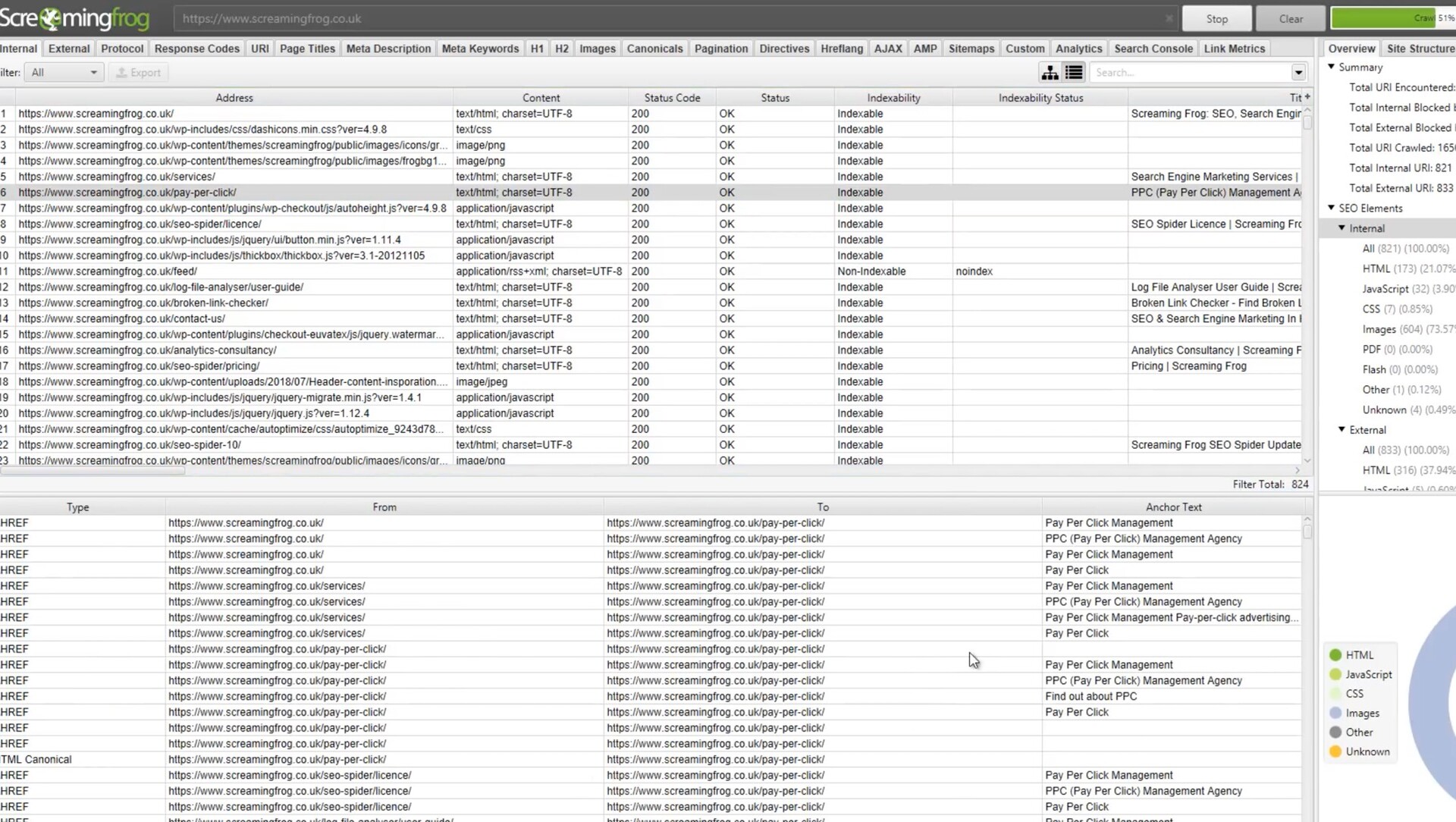
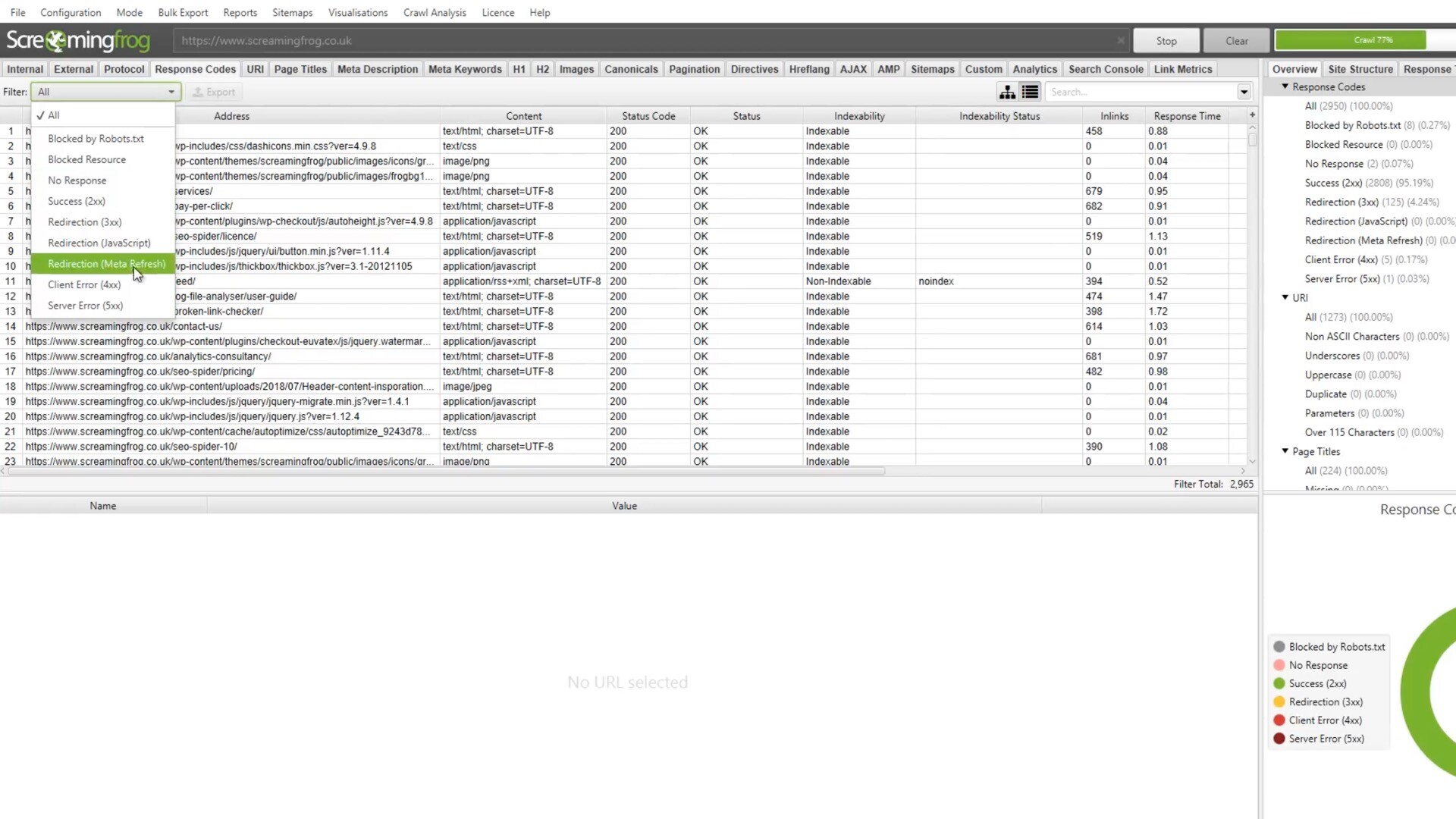
Screaming Frog SEO Spider是一款专业的SEO优化工具,它可以帮助用户快速地分析网站的结构和内容,发现潜在的SEO问题,并提供优化建议。它支持Windows和Mac操作系统,可以在本地计算机上运行,不需要联网。
Screaming Frog SEO Spider for Mac是专门为Mac用户设计的版本,它与Mac操作系统完美兼容,界面简洁、易于使用。它可以扫描网站的所有页面,包括HTML、CSS、JavaScript和图片等,分析网站的内部链接和外部链接,检查页面的标题、描述、关键词、头部标签等元素是否符合SEO最佳实践,发现页面的404错误、重定向、重复内容等问题,提供优化建议和报告。
Screaming Frog SEO Spider for Mac适用于SEO优化师、网站管理员、开发人员等需要优化网站SEO的用户。测试环境:MacOS 14.0
Screaming Frog SEO Spider Mac版破解教程
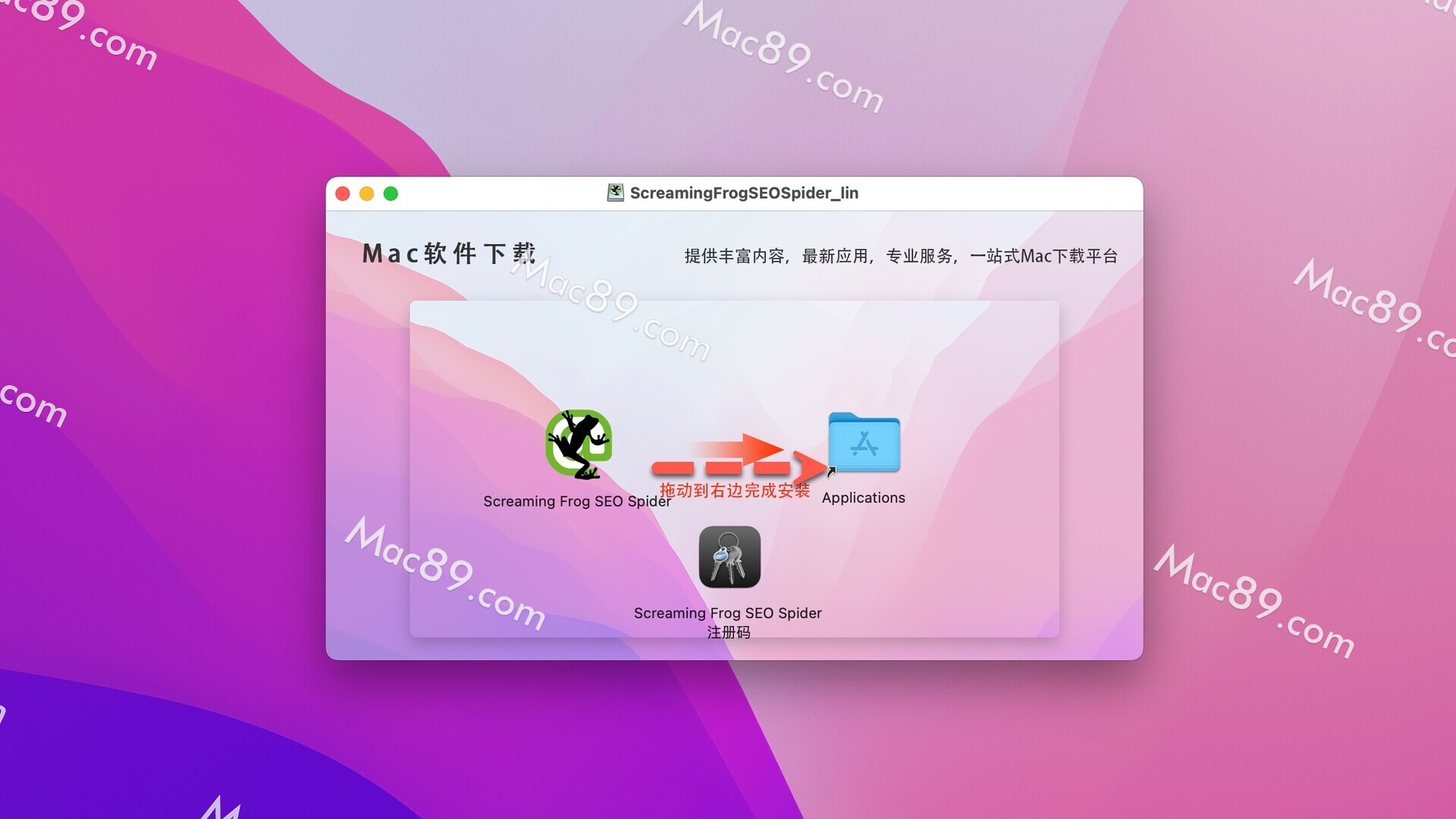
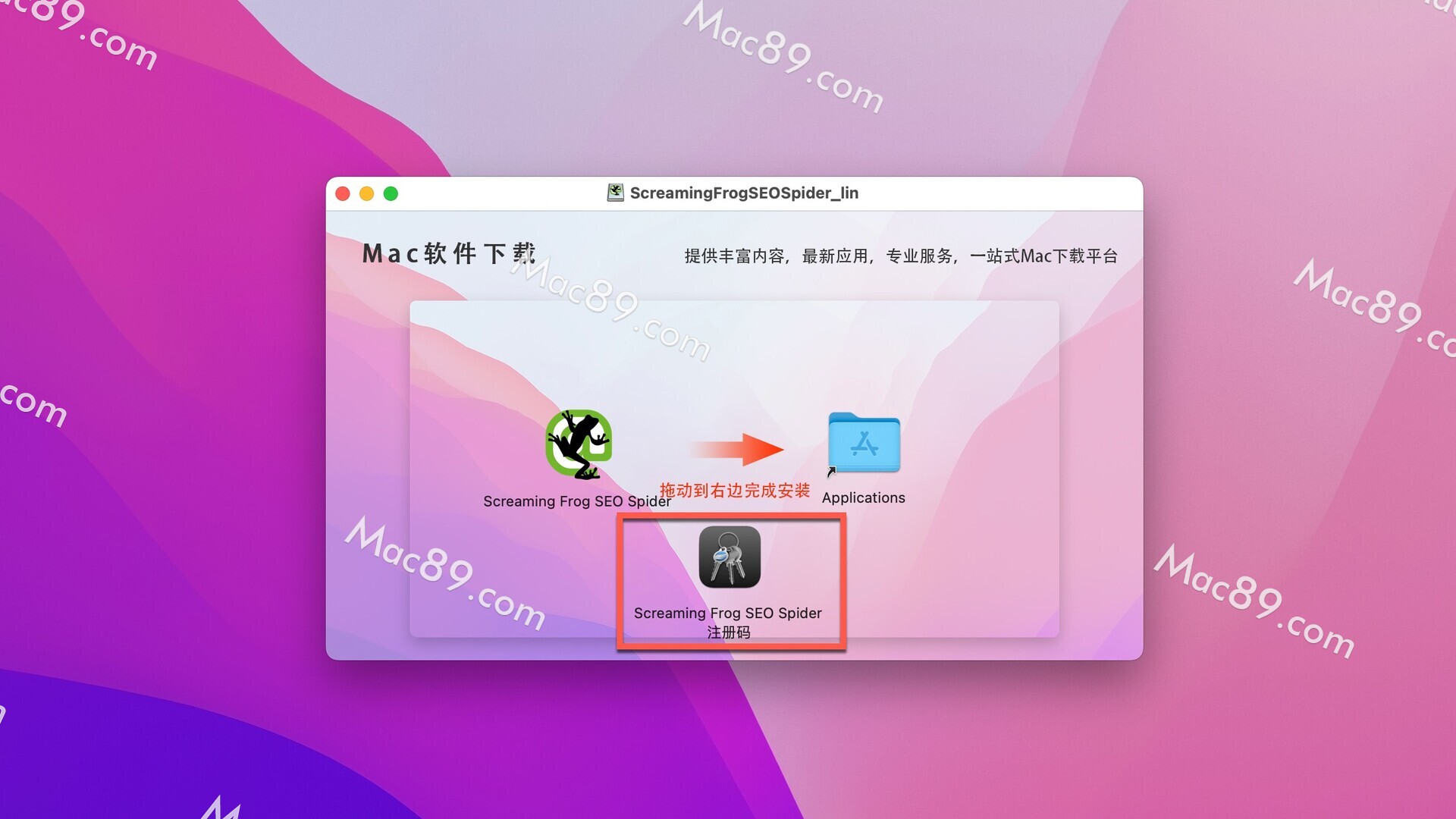
seo spider破解版镜像包下载完成后,双击打开镜像包,将左侧的Screaming Frog SEO Spider拉到右侧应用程序中,如图:
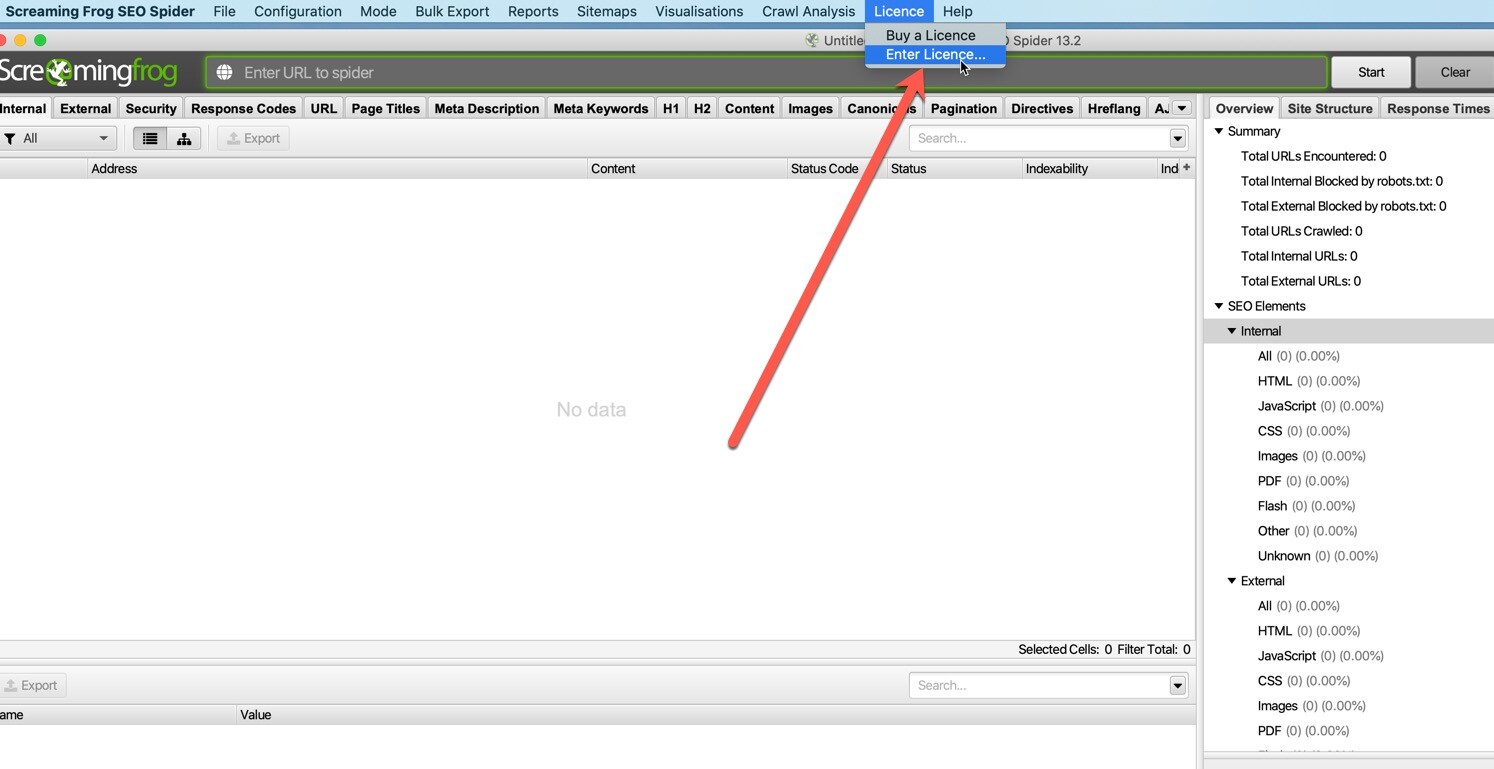
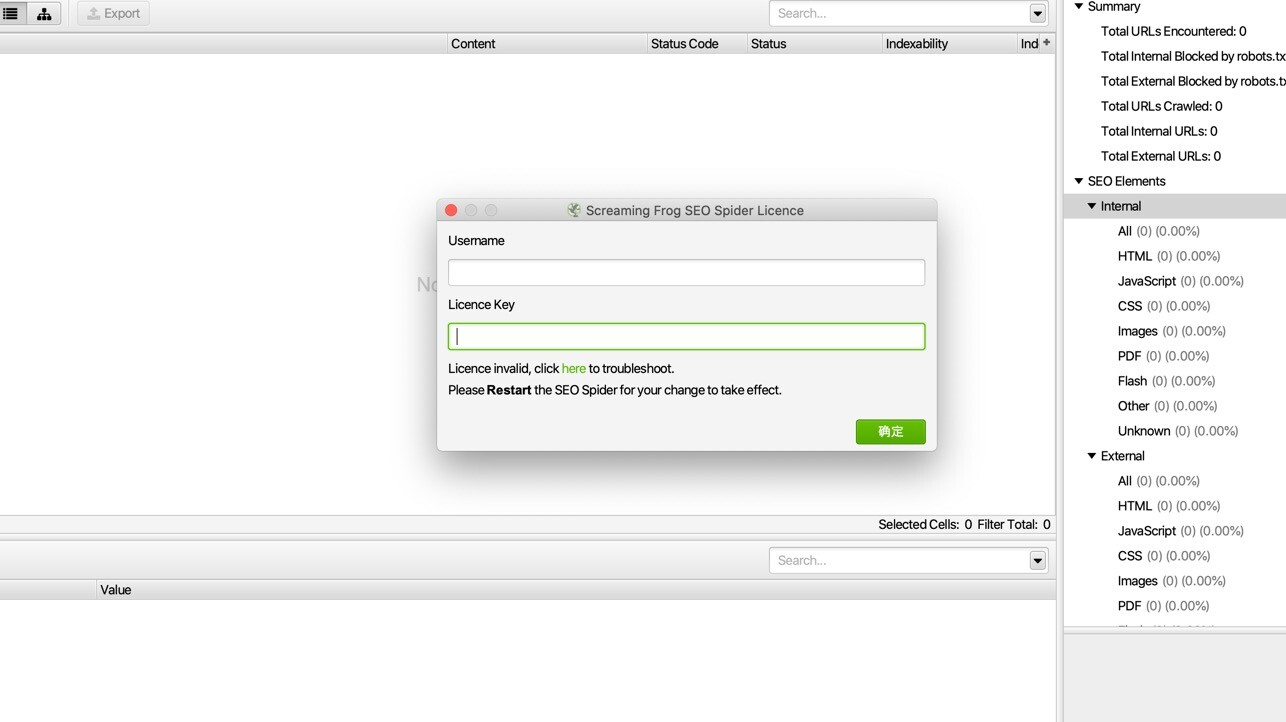
打开SEO Spider,在顶部菜单栏打开licence,然后点击enter licence,如图:
弹出seo spider mac版注册界面,放到一边
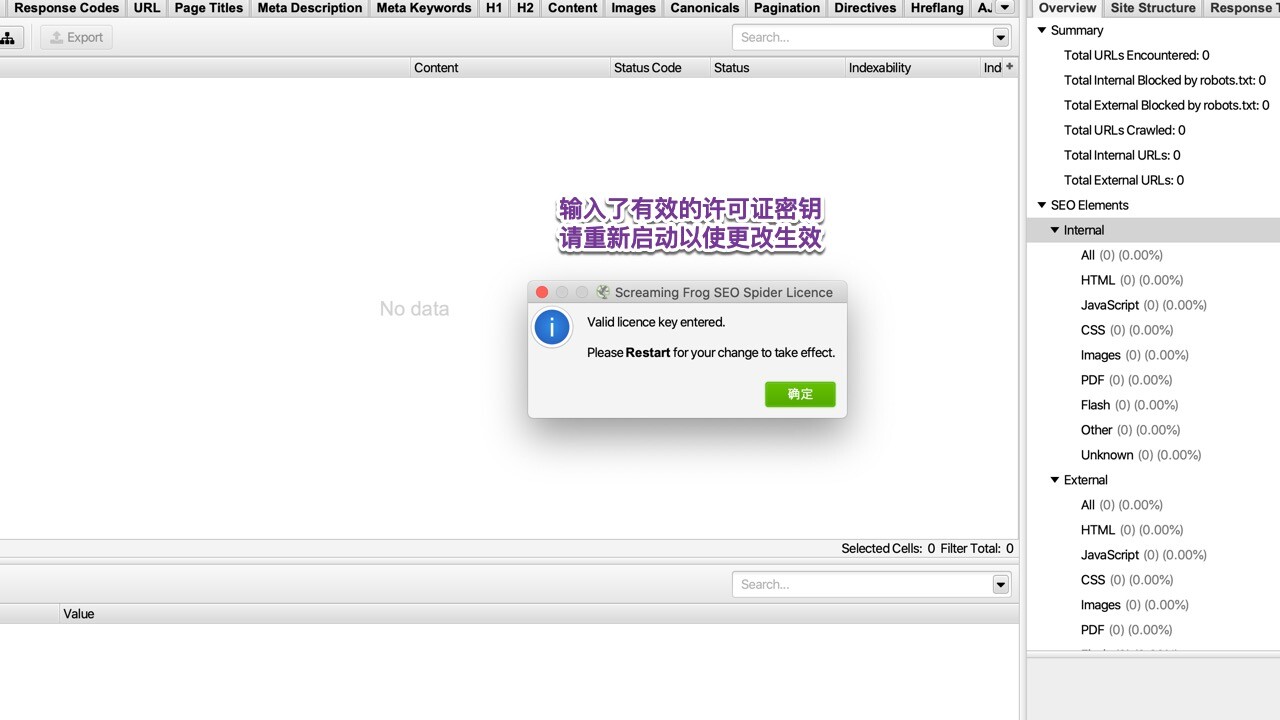
返回镜像包打开Screaming Frog SEO Spider注册码,如图:
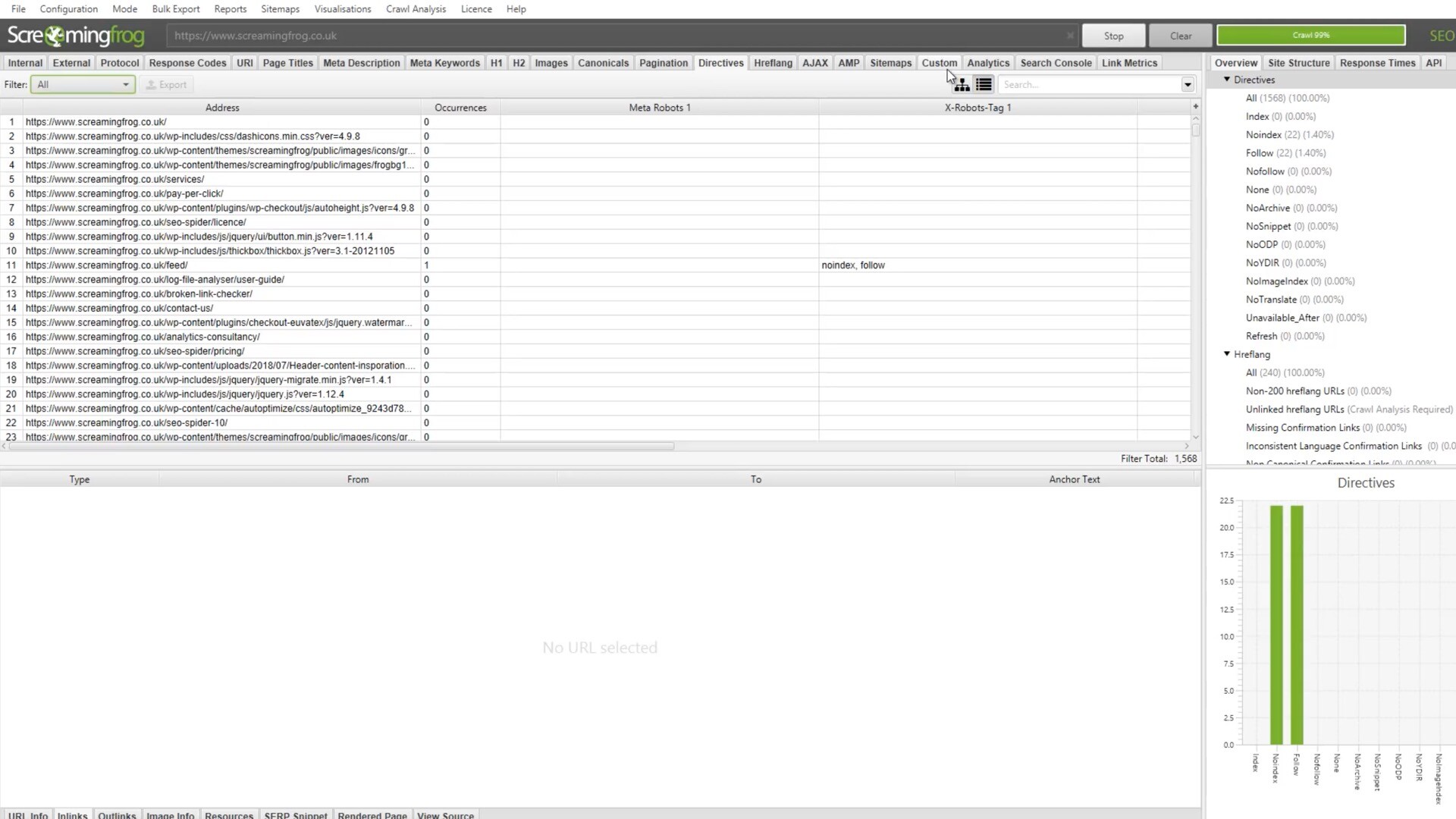
将注册码复制粘贴到SEO Spider注册界面,然后点击确定即可,如图:
seo spider mac破解版功能介绍
1.找到断开的链接
立即抓取网站并找到损坏的链接(404s)和服务器错误。批量导出要修复的错误和源URL,或发送给开发人员。
2.分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别网站中过长,短缺,缺失或重复的内容。
3.使用XPath提取数据
使用CSS Path,XPath或regex从网页的HTML中收集任何数据。这可能包括社交元标记,其他标题,价格,SKU或更多!
4.生成XML站点地图
快速创建XML站点地图和图像XML站点地图,通过URL进行高级配置,包括上次修改,优先级和更改频率。
5.抓取JavaScript网站
使用集成的Chromium WRS渲染网页,以抓取动态的,富含JavaScript的网站和框架,例如Angular,React和Vue.js.
6.审核重定向
查找临时和永久重定向,识别重定向链和循环,或上传URL列表以在站点迁移中进行审核。
7.发现重复内容
使用md5算法检查发现完全重复的URL,部分重复的元素(如页面标题,描述或标题)以及查找低内容页面。
8.审查机器人和指令
查看被robots.txt,元机器人或X-Robots-Tag指令阻止的网址,例如'noindex'或'nofollow',以及规范和rel =“next”和rel =“prev”。
9.与Google Analytics集成
连接到Google AnalyticsAPI并针对抓取功能获取用户数据,例如会话或跳出率和转化次数,目标,交易和抓取页面的收入。
10.可视化站点架构
使用交互式爬网和目录强制导向图和树形图站点可视化评估内部链接和URL结构。
Screaming Frog SEO Spider Mac版更新日志
我们很高兴地宣布Screaming Frog SEO Spider 版本 18.0,内部代号为“Willow”。
我们一直忙于开发我们希望在圣诞节假期前发布的一项主要功能,以及各种较小但需求量很大的功能和改进。
更新内容
1) GA4 整合
这花了一些时间,但与大多数 SEO 一样,我们终于达成共识,我们必须实际切换到 GA4。您现在可以(不情愿地)连接到 GA4 并通过他们的新 API 抓取分析数据。
通过“配置 > API 访问 > GA4”连接,从 65 个可用指标中进行选择,并调整日期和维度。
GA4 指标
与现有的 UA 集成类似,当您开始实时抓取时,数据将快速出现在“分析”和“内部”选项卡下。
GA4 集成到 SEO 蜘蛛
您可以像在 GA UI 中一样应用“过滤器”维度,包括第一位用户,或使用维度值的会话渠道分组,例如“有机搜索”以优化特定渠道。
如果您希望支持任何其他维度或过滤器,请告诉我们。
2) 解析 PDF
PDF 并不是世界上最性感的东西,但由于多年来提出此要求的公司和教育机构数量众多,我们感到有必要提供解析它们的支持。SEO Spider 现在将抓取 PDF,发现其中的链接并将文档标题显示为页面标题。
这意味着用户可以检查 PDF 中的链接是否按预期运行,并且链接断开等问题将以通常的方式在“响应代码”选项卡中报告。外链选项卡将被填充,并包括详细信息,例如响应代码、锚文本,甚至是链接所在的 PDF 页面。
解析 PDF
您还可以在“Config > Spider > Extraction”下选择“Extract PDF Properties”和“Store PDF”,PDF 主题、作者、创建和修改日期、页数和字数将被存储。
收集的 PDF 属性
可以通过“批量导出 > Web > 所有 PDF 文档”批量保存和导出 PDF。
如果您对搜索引擎如何抓取和索引 PDF 感兴趣,请查看几条推文,我们在推文中分享了Google和Bing内部实验的一些见解。
3) 验证选项卡
有一个新的验证选项卡,它执行一些基本的最佳实践验证,这些验证会在爬网和索引时影响爬虫。这不是有点过于严格的 W3C HTML 验证,此选项卡的目的是确定可能影响搜索机器人可靠地解析和理解页面的问题。
验证选项卡
大多数 SEO 都知道head 中的无效 HTML 元素会导致它提前关闭,但是如果在 head 之前看到非 head 元素,Chrome(以及随后的)Google 等浏览器还会执行其他有趣的修复和怪癖HTML(它创建自己的空白头),或者如果有多个或缺少 HTML 元素等。
新的过滤器包括——
中的无效 HTML 元素 – 中包含无效 HTML 元素的页面。当 中使用了无效元素时,Google 会假定 元素结束并忽略出现在无效元素之后的所有元素。这意味着将不会看到出现在无效元素之后的关键 元素。根据 HTML 标准, 元素仅保留用于 title、meta、link、script、style、base、noscript 和 template 元素。
不是 元素中的第一个 – 带有 HTML 元素的页面在 HTML 中的 元素之后。 应该是 元素中的第一个元素。浏览器和 Googlebot 将自动生成一个 元素,如果它不是 HTML 中的第一个元素。虽然理想情况下 元素应该在 中,但如果有效的 元素位于 中的第一个,它将被视为生成的 的一部分。但是,如果在预期的 元素及其元数据之前使用了非 元素(例如
、、 等),则 Google 会假定 元素结束。这意味着预期的 元素及其元数据只能在 中看到并被忽略。
缺少 标记– 页面在 HTML 中缺少 元素。 元素是页面元数据的容器,位于 和 标记之间。元数据用于定义页面标题、字符集、样式、脚本、视口和其他对页面至关重要的数据。如果标记中省略了 元素,浏览器和 Googlebot 将自动生成该元素,但是它可能不包含对页面有意义的元数据,因此不应依赖该元素。
多个 标签– HTML 中包含多个 元素的页面。HTML 中应该只有一个 元素,它包含文档的所有关键元数据。浏览器和 Googlebot 将合并来自后续 元素的元数据(如果它们都在 之前),但是,不应依赖这一点并且可能会出现混淆。 开始后的任何 标签都将被忽略。
缺少 标记– 页面在 HTML 中缺少 元素。 元素包含页面的所有内容,包括链接、标题、段落、图像等。页面的 HTML 中应该有一个 元素。如果标记中省略了 元素,浏览器和 Googlebot 将自动生成它,但是,不应依赖于此。
多个 标签– 在 HTML 中包含多个 元素的页面。HTML 中应该只有一个 元素包含文档的所有内容。浏览器和 Googlebot 将尝试合并来自后续 元素的内容,但是,不应依赖这一点并且可能会出现混淆。
超过 15MB 的HTML 文档– 文档大小超过 15MB 的页面。这一点很重要,因为 Googlebot 将它们的抓取和索引限制在 HTML 文件或支持的基于文本的文件的前 15MB。此大小不包括 HTML 中引用的资源,例如单独获取的图像、视频、CSS 和 JavaScript。Google 仅考虑将文件的前 15MB 编入索引,然后停止抓取。文件大小限制适用于未压缩的数据。HTML 文件的中值大小约为 30 KB,因此页面极不可能达到此限制。
我们计划随着时间的推移扩展我们的验证检查和过滤器。
4) 应用内更新
每次我们发布更新时,总会有一两个用户提醒我们,他们必须费尽心思访问我们的网站,然后点击按钮下载并安装新版本。
为什么我们要让他们经受这种折磨?
简单的答案是,从历史上看,我们认为这没什么大不了的,而且优先考虑我们可以构建的许多其他超酷功能,这有点无聊。话虽如此,我们确实听取了用户的意见,因此我们继续并优先考虑无聊但有用的功能。
当有新版本可用时,您现在会在应用程序内收到提醒,该版本已经在后台静默下载。然后,您只需单击几下即可安装。
SEO 蜘蛛中的应用内更新
我们正计划切换我们的安装程序,因此安装和自动重启所需的点击次数也将很快实现。我们几乎无法抑制自己的兴奋。
5) 调度/CLI 认证
以前,通过调度或 CLI 进行身份验证的唯一方法是通过 HTTP 标头配置提供带有用户名和密码的“授权”HTTP 标头,这适用于基于标准的身份验证——而不是 Web 表单。
我们现在已经使这变得更加简单,不仅适用于基本或摘要身份验证,还适用于 Web 表单身份验证。在“配置 > 身份验证”中,您现在可以为任何基于标准的身份验证提供用户名和密码,系统会记住这些用户名和密码,因此您只需提供一次。
基于 SEO Spider 标准的身份验证
您也可以像往常一样通过“基于表单”的身份验证登录,cookie 将被存储。
网络表单认证
提供相关详细信息或登录后,您可以访问新的“配置文件”选项卡,并导出新的 .seospiderauthconfig 文件。
SEO 蜘蛛身份验证配置文件
然后可以在调度或 CLI 中提供此文件,该文件已为基于标准和基于表单的身份验证保存了身份验证。
在调度中提供身份验证
这意味着对于计划或自动抓取,SEO Spider 不仅可以登录基于标准的身份验证,还可以在可行的情况下登录 Web 表单。
6) 新过滤器和问题
现有选项卡中有各种新的过滤器和问题可用,有助于更好地过滤数据或交流发现的问题。
新的重定向链过滤器
其中许多已经可以通过另一个过滤器或现有报告(如“重定向链”)获得。但是,他们现在在 UI 中有自己的专用过滤器和问题,以帮助提高认识。这些包括 -
'Response Codes > Redirect Chains' – 重定向到另一个 URL 的内部 URL,然后该 URL 也进行重定向。这可以连续发生多次,每次重定向都称为“跃点”。可以通过“报告 > 重定向 > 重定向链”查看和导出完整的重定向链。
'Response Codes > Redirect Loop' – 重定向到另一个 URL 的内部 URL,然后该 URL 也进行重定向。这可以连续发生多次,每次重定向都称为“跃点”。只有当 URL 重定向到重定向链中的前一个 URL 时,才会填充此过滤器。可以通过“报告 > 重定向 > 重定向链”查看和导出带循环的重定向链,并将“循环”列过滤为“真”。
'Images > Background Images' – 在整个网站上发现的 CSS 背景和动态加载的图像,应用于非关键和装饰目的。背景图像通常不会被谷歌索引,浏览器不会为辅助技术提供背景图像上的 alt 属性或文本。
“Canonicals > Multiple Conflicting” ——为一个 URL 设置了多个 canonicals 的页面,这些 URL 指定了不同的 URL(通过多个链接元素、HTTP 标头或两者结合)。这可能会导致不可预测性,因为页面的单个实现(链接元素或 HTTP 标头)应该只设置一个规范 URL。
'Canonicals > Canonical Is Relative' – 具有相对而非绝对 rel=”canonical” 链接标签的页面。虽然该标记与许多 HTML 标记一样接受相对 URL 和绝对 URL,但很容易在相对路径上出现细微错误,从而导致与索引相关的问题。
'Canonicals > Unlinked' – 只能通过 rel=”canonical” 发现并且不能通过网站上的超链接链接到的 URL。这可能是内部链接或规范中包含的 URL 出现问题的迹象。
“链接 > 仅非索引页面内链接”——仅从不可索引的页面链接到的可索引页面,包括 noindex、canonicalised 或 robots.txt 不允许的页面。带有 noindex 的页面及其链接最初会被抓取,但是 noindex 页面将从索引中删除,并且随着时间的推移被抓取的次数会减少。来自这些页面的链接也可能被较少地抓取,Google 员工一直在争论是否会继续对链接进行计数。来自规范化页面的链接最初可以被抓取,但如果索引和链接信号按照规范中的指示传递到另一个页面,则 PageRank 可能无法按预期流动。这可能会影响发现和排名。无法抓取 Robots.txt 页面,因此不会看到来自这些页面的链接。
7) Flesch 可读性分数
现在计算 Flesch 可读性分数并将其包含在“内容”选项卡中,其中包含“可读性困难”和“可读性非常困难”的新过滤器。
Flesch 可读性分数
请注意,可读性分数适用于英语,我们将来可能会提供对其他语言的支持或其他语言的替代可读性分数。
可读性分数可以在“Config > Spider > Extraction”下禁用。
其他更新
自动完成网址栏
URL 栏现在将根据以前的 URL 栏历史记录在您键入时显示建议的 URL,用户可以快速选择这些 URL 以帮助节省宝贵的时间。
网址栏自动完成
可视化的响应代码颜色
您现在可以在抓取可视化中选择“使用响应代码节点颜色” 。
这意味着无响应的节点、2XX、3XX、4XX 和 5XX 存储桶将单独着色,以帮助用户更有效地发现与响应相关的问题。
可视化的响应代码颜色
计划中的 XML 站点地图源
您现在可以选择一个 XML 站点地图 URL 作为计划中的源,并像常规 UI 一样通过列表模式中的 CL。
用于计划的 XML 站点地图源
18.0 版还包括一些较小的更新和错误修复。
300 万个 Google 丰富结果功能更新,用于结构化数据验证。
Apache-Common-Text 文件已针对漏洞 CVE-2022-42889 更新 > 1.10.0。
相关软件
-

Scrutiny for Mac(网站分析检测工具)
v12.8.3激活版
2023-12-20 3.94 MB -

Internet Status for Mac(网络连接状态查看工具)
v5.6激活版
2023-06-14 8.67 MB -

Wireshark for Mac(网络协议分析软件)
v4.3.0rc0中文免费版
2023-12-22 63.27 MB -

Netler for mac(网络监视器)
v2.0激活版
2020-11-12 5.94 MB -

Screaming Frog Log File Analyser for Mac(日志文件分析器)
v5.3激活版
2023-01-09 156.55 MB

客服QQ:

客服微信

 后退
后退